Hola,
Realmente es un buen intento de construir un pipeline completo, pero hay varios puntos importantes que revisar. Vamos capa por capa:
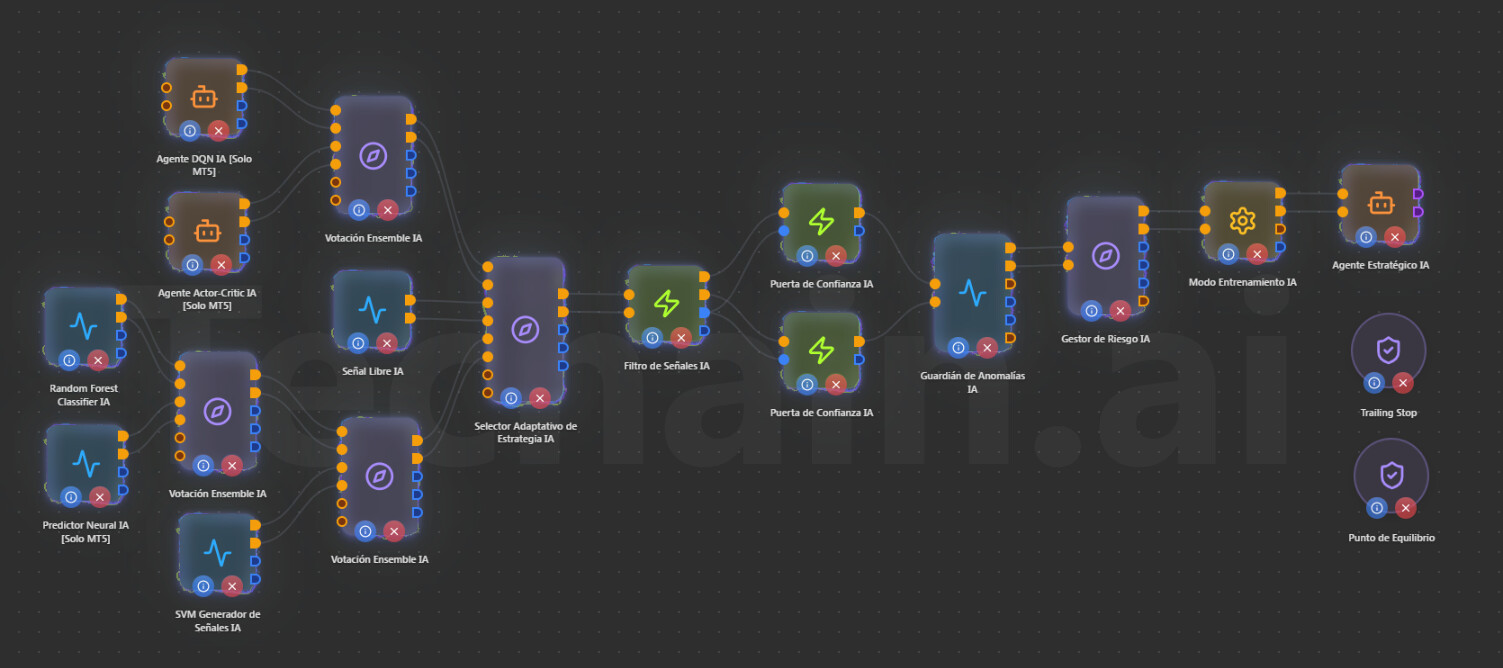
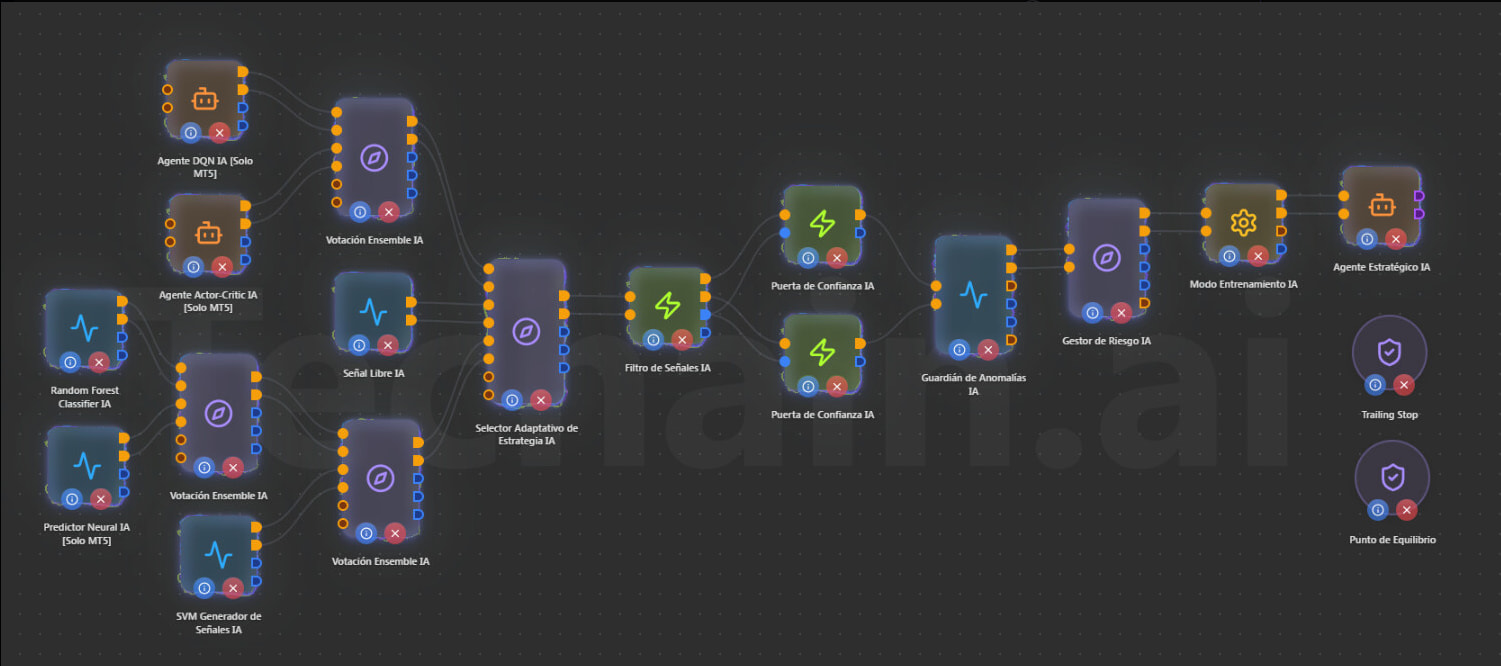
Capa 1 - Generadores de Señales (5 nodos): Bien planteado
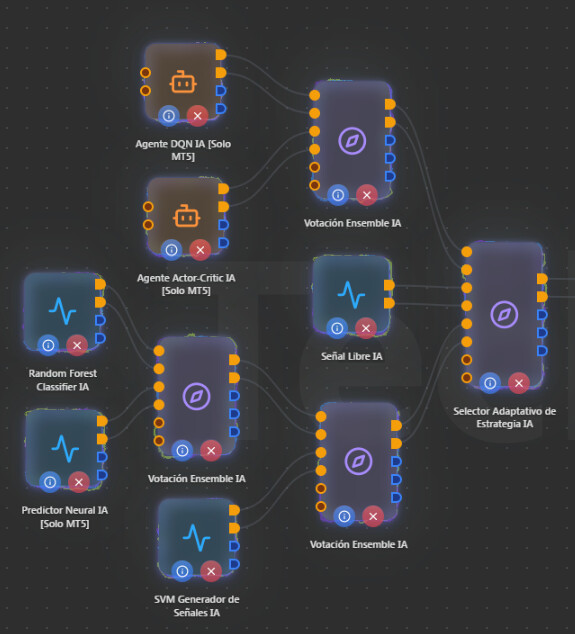
Tienes 5 generadores de señales de IA de diferentes familias:
-
Agente DQN IA (Reinforcement Learning - Deep Q-Network)
-
Agente Actor-Critic IA (Reinforcement Learning - A2C)
-
Random Forest Classifier IA (Machine Learning clásico)
-
Predictor Neural IA (LSTM Reservoir Computing)
-
SVM Generator de Señales IA (Support Vector Machine)
La diversidad es buena: combinar RL, ML clásico y redes neuronales aporta perspectivas diferentes sobre el mercado.
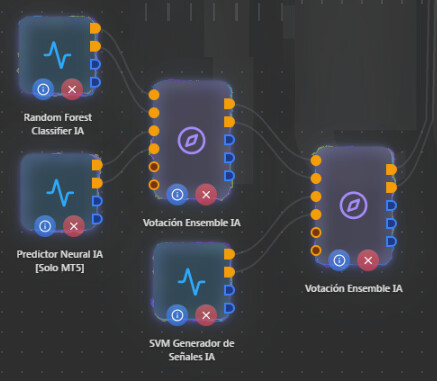
Capa 2 - Tres Votaciones Ensemble: Revisar distribución
Cada nodo de Votación Ensemble IA acepta hasta 3 estrategias (3 pares buy/sell). Tienes 5 generadores repartidos en 3 Ensembles. Aquí hay un punto clave: si alguno de los Ensembles recibe solo 1 estrategia, ese Ensemble no aporta nada - no hay votación posible con 1 sola voz, simplemente pasa la señal sin filtrar.
La distribución más óptima por funcionamiento sería:
-
Ensemble 1: DQN + Actor-Critic (ambos RL, se complementan bien)
-
Ensemble 2: Random Forest + SVM + Predictor Neural (los 3 de ML/clasificación)
Con esa distribución necesitarías solo 2 Ensembles en lugar de 3, y cada uno tendría suficientes estrategias para que la votación sea significativa.
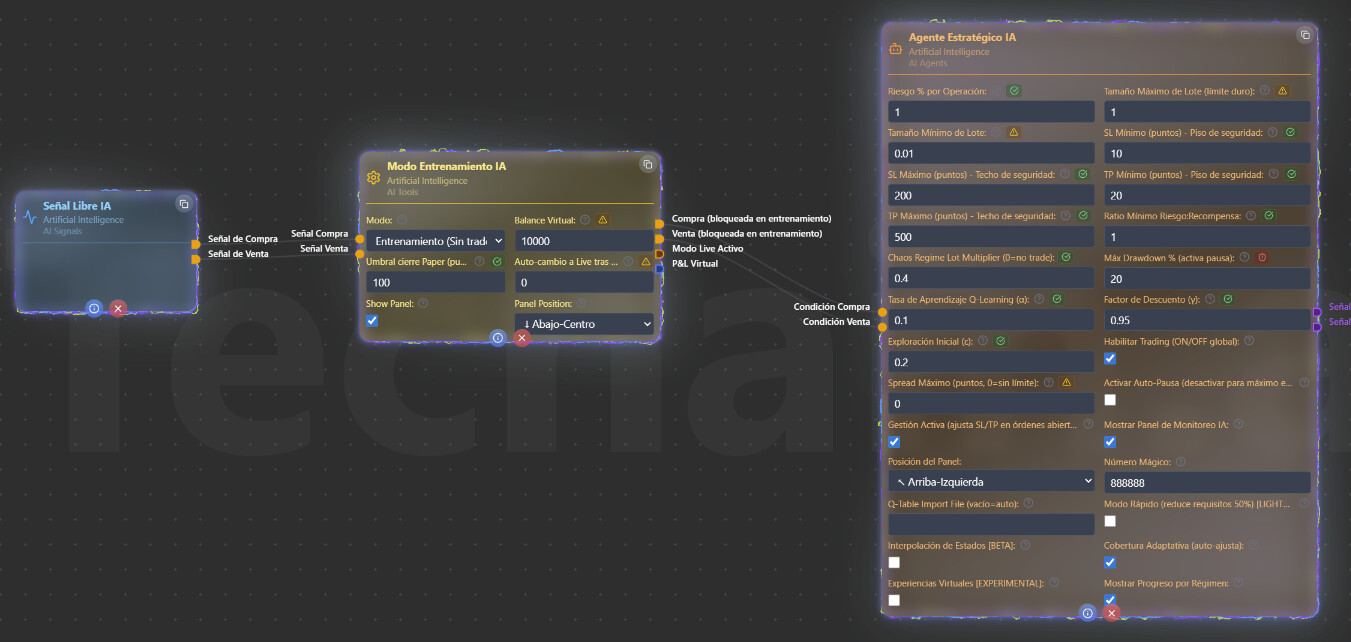
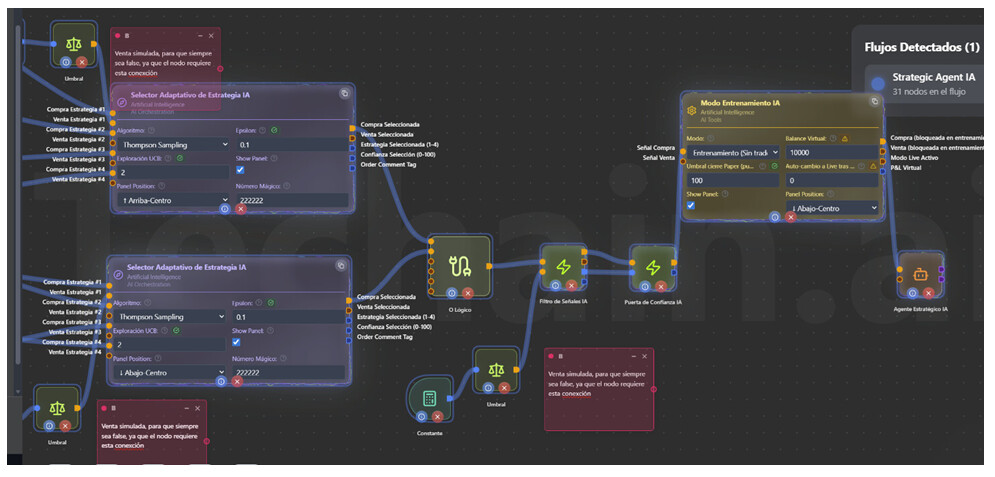
Capa 3 - Señal Libre IA: PROBLEMA
Aquí está el problema principal del modelo. El nodo Señal Libre IA genera señales que siempre son true, y cuando se conecta al Agente Estratégico IA, activa el modo autónomo donde el agente toma decisiones propias y todas las señales externas pasan a ser “hints” suaves (solo ajustan probabilidades un ~10%).
Esto significa que todo tu pipeline elaborado (5 generadores + 3 Ensembles + Selector + Filtro + Puertas de Confianza + Guardián + Gestor de Riesgo + Modo Entrenamiento) quedaría prácticamente anulado porque el Agente Estratégico lo ignoraría en gran medida al estar en modo autónomo.
Si buscas que aplique todo, debes eliminar el nodo Señal Libre IA. Tu pipeline ya tiene suficiente inteligencia sin necesidad de activar el modo autónomo.
Capa 3b - Selector Adaptativo de Estrategia IA: Buena idea
El Selector Adaptativo usa un algoritmo Multi-Armed Bandit (Thompson Sampling/UCB1) para elegir dinámicamente la mejor estrategia. Acepta hasta 4 estrategias. Conectar las salidas de los 2-3 Ensembles al Selector es una idea sólida, el Selector aprenderá cuál Ensemble rinde mejor en cada régimen de mercado y priorizará sus señales.
Capa 4 - Filtro de Señales IA + Puerta de Confianza IA (x2): Correcto
El orden Selector → Filtro → Puertas de Confianza es correcto:
Asegúrate de conectar:
Capa 5 - Guardián de Anomalías IA: Buena ubicación
El Guardián detecta flash crashes, gaps extremos, spikes de volatilidad y spreads anormales. Colocarlo después de las Puertas de Confianza y antes del Gestor de Riesgo es correcto, actúa como red de seguridad final antes de la ejecución.
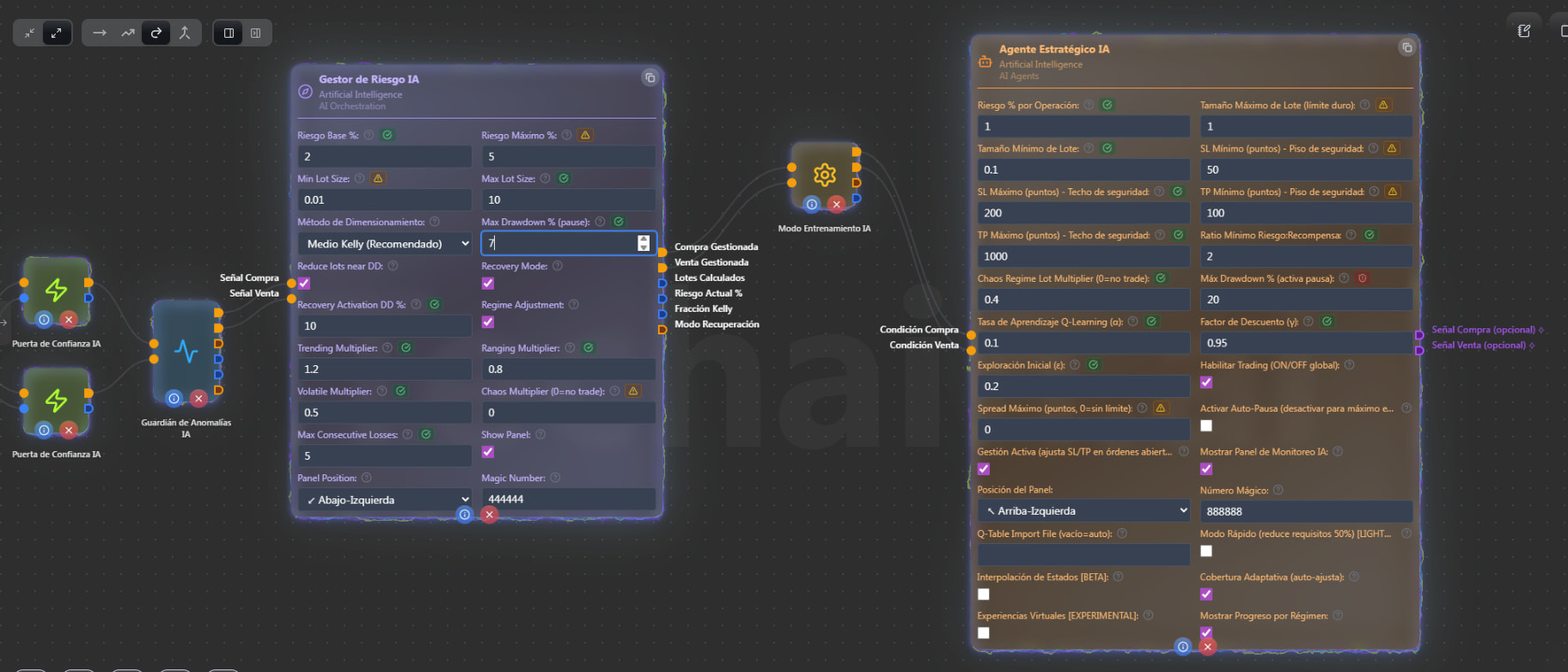
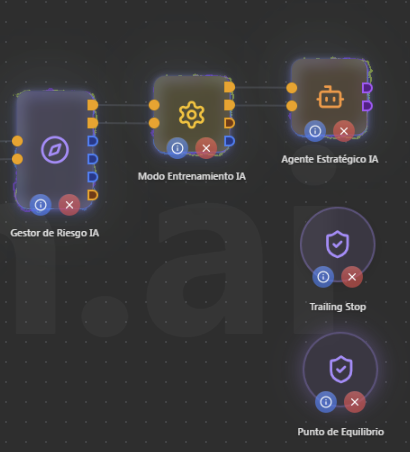
Capa 6 - Gestor de Riesgo IA + Modo Entrenamiento IA: Correcto
-
El Gestor de Riesgo calcula el tamaño de lote dinámico con Kelly Criterion y protección de drawdown
-
El Modo Entrenamiento te permite pasar por fases: Training (solo observación) → Paper Trading (virtual) → Live
El orden Gestor de Riesgo → Modo Entrenamiento → Agente Estratégico es correcto.
Capa 7 - Agente Estratégico IA + Trailing Stop + Punto de Equilibrio: Correcto
El Agente Estratégico recibe las señales finales y ejecuta. El Trailing Stop y Punto de Equilibrio son nodos independientes que gestionan las órdenes abiertas automáticamente. Están bien colocados.
PROBLEMA PRINCIPAL: Pipeline demasiado largo
Tu modelo tiene 8-9 capas de procesamiento entre la señal original y la ejecución:
Generadores → Ensembles → Selector → Filtro → Puertas → Guardián → Gestor Riesgo → Modo Entrenamiento → Agente Estratégico
Cada capa filtra señales, lo que significa que muy pocas operaciones llegarán al final. Esto puede resultar en un bot que casi nunca opera.
Cambios clave:
-
Eliminar Señal Libre IA (conflicto con el pipeline)
-
2 Ensembles en lugar de 3 (evitar Ensemble con 1 sola estrategia)
-
Guardián de Anomalías puede quedarse si quieres la capa de seguridad extra
-
Gestor de Riesgo ya está integrado dentro del Agente Estratégico (calcula SL/TP/lotaje dinámicamente), así que es redundante como nodo separado a menos que quieras una capa adicional de control de drawdown
-
Modo Entrenamiento es útil si vas a pasar por fases de aprendizaje, pero no es necesario en producción
Con esto reduces el pipeline a 5 capas, que sigue siendo robusto pero permitirá que más operaciones de calidad se ejecuten. La idea es excelente y se nota el esfuerzo, pero el modelo tiene demasiadas capas de filtrado que pueden ahogar las señales. Elimina el Señal Libre, consolida los Ensembles, y tendrás un sistema muy potente.
Un saludo,
Ignacio
Un saludo,
Ignacio