Hola,
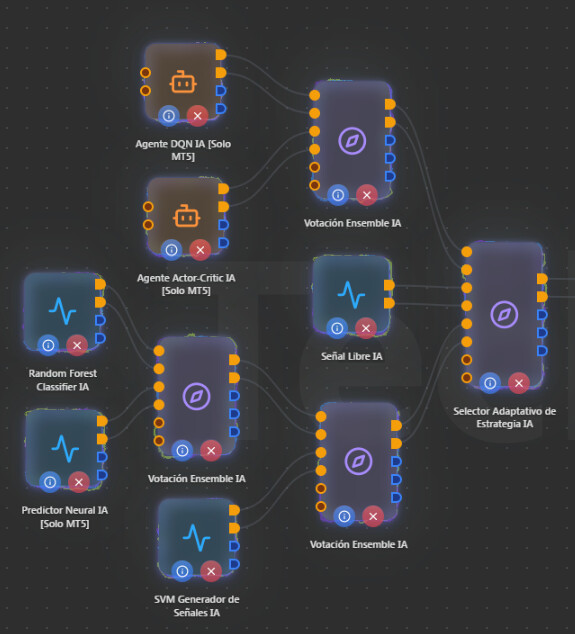
Tu duda es, si en el último paso, ¿mejor Selector o Votación Ensemble?
Lo más lógico para el flujo del EA o más adecuado, es un nodo de Votación Ensemble IA al final.
Motivos:
- Objetivo “super generación de señales”
Quieres unir las 5 fuentes y filtrar.
-
Con Selector al final: en cada momento solo usas una de las dos ramas (la que “va mejor” por rendimiento histórico). La otra rama se ignora. No estás “uniendo” las 5 señales en la última etapa, sino eligiendo una de dos bloques.
-
Con Ensemble al final: las dos ramas votan (con pesos adaptativos). La señal final es consenso de RL y ML+Libre.
Para “filtrar las 5 señales” en el sentido de combinar y refinar, el comportamiento del Ensemble encaja mejor que el del Selector en ese último paso.
- Uso óptimo de cada uno
-
Selector es ideal cuando tienes varias estrategias alternativas y quieres que el sistema elija una (la que mejor rinde últimamente). No para “sumar” señales.
-
Ensemble es ideal cuando quieres una sola decisión a partir de varias opiniones (votación/consenso). Eso es justo lo que tienes, 2 opiniones agregadas (RL y ML+Libre) que quieres fusionar en una super señal.
- Configuración práctica del Ensemble final
-
Con 2 entradas (tu rama RL y tu rama ML+Libre), el Ensemble puede usar método Weighted o Majority.
-
Con pesos adaptativos activados, las ramas que vayan mejor irán teniendo más peso. Así sigues teniendo “adaptación al mejor resultado” pero sin descartar la otra rama, solo le das menos peso si rinde peor.
¿Selector al final? Tiene sentido si tu objetivo es “en cada momento solo quiero seguir o la rama RL o la rama ML+Libre, la que mejor esté rindiendo.”
¿Ensemble al final? Tiene sentido si tu objetivo es “quiero una sola señal que sea el consenso de la rama RL y de la rama ML+Libre, con posibilidad de que una pese más que la otra (pesos adaptativos).”
Para “unir las 5 señales y filtrarlas” en una super señal, la opción más alineada es Votación Ensemble IA en ese último paso, manteniendo la estructura de Ensembles que ya tienes antes (por limitación de 3 estrategias por Ensemble). Así la señal final sigue siendo “combinación por consenso” en lugar de “solo una de las dos ramas”.
Un saludo,
Ignacio
1 me gusta
Hola,
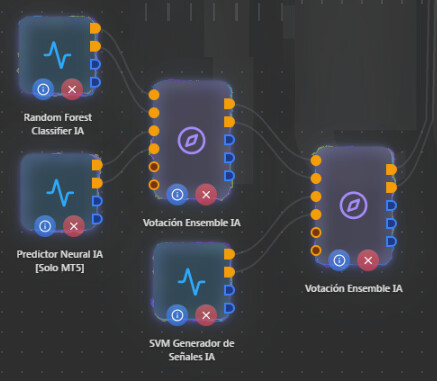
Sí, puedes conectar Random Forest, Predictor Neural y SVM a un solo nodo de Votación Ensemble IA. No hace falta usar dos Ensembles en cascada.
Por qué:
- Un Ensemble = hasta 3 estrategias
El nodo Votación Ensemble IA tiene 3 “slots”: Estrategia #1, #2 y #3 (cada una con señal de compra y de venta).
-
Estrategia #1 → Random Forest (buy + sell)
-
Estrategia #2 → Predictor Neural (buy + sell)
-
Estrategia #3 → SVM (buy + sell)
Con eso ya tienes las tres fuentes votando en un solo nodo.
- Tu configuración actual (dos Ensembles)
-
Primer Ensemble: recibe correctamente los 3 generadores y hace la votación.
-
Segundo Ensemble: solo recibe la salida del primero (una sola “estrategia”). Con una sola entrada no hay votación real, solo repite la misma señal y añade otro panel.
Por tanto, el segundo Ensemble sobra, no aporta lógica nueva y suma complejidad.
“Predictor Neural + Random Forest con Votación Ensemble” y “Random Forest + SVM” encajan en la misma idea: combinar por consenso varias señales.
La forma más simple y coherente es un único Ensemble donde entren las tres: Random Forest, Predictor Neural y SVM.
Ventajas:
-
Un solo panel de Ensemble.
-
Menos nodos y menos complejidad en el BOT.
-
Misma idea que la documentación, consenso entre los tres generadores.
-
Evitas un segundo Ensemble que no hace votación real.
Puedes poner Random Forest, Predictor Neural y SVM todos en un único Votación Ensemble IA; quita el segundo Ensemble. Es la forma más simple y alineada con la documentación.
Un saludo,
Ignacio
3 Me gusta
Hola. De acuerdo con tu experiencia, ¿qué funciona mejor a largo plazo? Sé que depende de muchos factores, pero a nivel general, si una persona sólo pudiese enfocarse en 1 sola cosa para trabajarla y especializarse, cuál sería la mejor opción?
- Estrategias discrecionales, optimizadas en MT5 y conectadas al Strategy Agent.
- Nodos de Señales IA (cada bot independiente): Random Forest Classifier IA, SVM Generador, Predictor Neural IA, Señal Libre, Agente DQN, Agente Actor Critic… Conectados al Strategy Agent.
Del mismo Timeframes: ¿Cuáles son los Timeframes más recomendados a la hora de usar:
- Strategy Agent con Estrategias discrecionales: 5M, 15M, 1H, etc?
- Nodos Señales IA: 5M, 15M, 1H, etc?
1 me gusta
Hola Rafa,
Te resumo por partes.
1. Si solo pudiera enfocarme en UNA cosa: ¿discrecionales + Agent o nodos Señales IA + Agent?
Me especializaría en estrategias discrecionales que yo definiese, optimizase en MT y conectase al Strategic Agent para que las gestionase en mi lugar.
Para mi es lo que más sentido tiene al inicio, si el objetivo es ser rentable y vivir del trading (o generar un ingreso o crecer la cuenta) en la mayor brevedad de tiempo con la menor carga de esfuerzo y dedicación:
-
Entiendes el edge. La ventaja son tus reglas (precio, indicadores, rupturas, etc.). Si falla, sabes qué revisar. Con nodos IA puros (DQN, Random Forest, etc.) el “por qué” de cada operación es más opaco, a la larga la IA creará mejores sistemas, más rentables y con menor riesgo, pero al inicio donde se quiere mayor agilidad para vivir de esto o ser rentable antes, necesitas poder explicar y corregir tu sistema sobre la marcha.
-
Un solo sistema mental. En lugar de depender de varias IAs (RF, SVM, DQN, Neural, etc.) que aun siendo mucho más profesional y efectivo, al principio la curva de aprendizaje es mayor, si lo simplificas, dominas una cadena “mi estrategia + el agente IA la adapta”. Menos ruido y más control cuando hay rachas malas. Se usa la IA pero de una forma más “fácil” para e intuitiva para el usuario. Todo sabiendo que al final del camino, el proceso obligará a coger el otro camino para poder seguir escalando la cuenta de trading, pero ya sería con otra mentalidad, resultados etc., y se lleva de otra forma, que ahora al inicio se quiere todo YA y eso provoca prisas, malas prácticas, atajos etc., y con un sistema puramente IA esto no es viable y lo quebrará. Require su tiempo.
-
Menos dependencia de datos y tiempo. El agente mejora con tus señales en 1–2 meses. DQN y Actor-Critic necesitan más tiempo y muchas operaciones para converger. Cuando uno se inicia, psicológicamente suele ser mejor algo que puedas validar y afinar en plazos razonables porque si no, se termina inventando y atajando por falta de disciplina o desesperación.
-
Control del riesgo. Una estrategia discrecional bien definida permite optimizar SL, TP y tamaño de posición de forma explícita por ejemplo para requerimientos específicos o una diversificación concreta. El agente adapta sobre esa base. Para vivir del trading, lo primero es no reventar la cuenta, eso se controla mejor con reglas que entiendes y has probado. Si el proceso inicial es más complejo y no se dedica el tiempo requerido al aprendizaje, es más fácil cometer algún error y liarla.
-
Escalabilidad. Una vez dominas “diseño → optimización → conexión al agente”, puedes repetir el proceso en otros activos o timeframes sin tener que dominar cinco tipos de IA a la vez.
Los nodos de Señales IA (Random Forest, SVM, Predictor Neural, DQN, Actor-Critic) tienen su sitio, pueden ser un siguiente paso más avanzado cuando ya se tenga una base rentable. La Señal Libre no es un bot aparte, es el nodo que, al conectar sus salidas al Strategic Agent, hace que el agente opere solo con su motor Q-Learning, sin otra estrategia conectada.
2. Timeframes
Strategic Agent (con estrategias discrecionales):
-
Los mejores: M30 o H1.
-
Para empezar usaría: H1, H4 (suficiente actividad, evitaría D1/semanal al principio).
-
Periodo mínimo de backtest para entrenar bien: 1 año.
Nodos de Señales IA (Random Forest, SVM, etc.):
-
Random Forest: documentación usa H1 como referencia (p. ej. 1000 barras para H1; lookAhead 5 en H1; scalping 1–3, swing 10–20).
-
SVM: 300–2000 barras según timeframe, lookAhead 3 (corto) a 10 (medio).
-
En la práctica: M15, M30, H1 son los más referenciados para tener datos suficientes sin irme a timeframes demasiado altos.
DQN / Actor-Critic (solo MT5):
Un saludo,
Ignacio
3 Me gusta
Buenísimo! Muchas gracias!
2 Me gusta
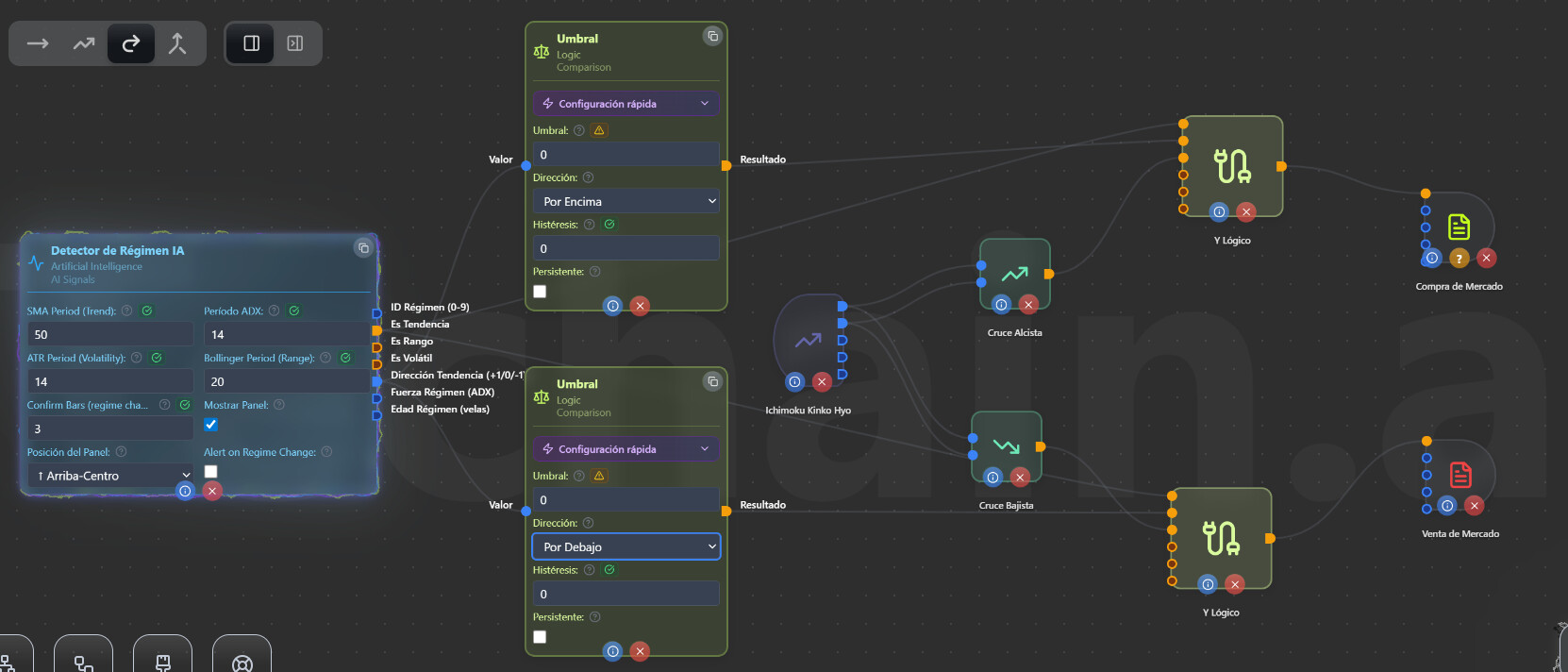
Hola. Seria correcto este modelado? Por otro lado, permite este nodo de regimen ser usado en un backtest? es decir, aunque no guarde aprendizaje, la pregunta es si genera si se podria backtestear u optimizar en el tester.
Hola Rafa,
El modelado está bien planteado.
Sobre el backtest, sí, el Detector de Régimen se puede usar sin problema en backtest y optimización. No guarda aprendizaje, todo es cálculo en barra (SMA, ADX, ATR, Bollinger) con datos históricos, así que es determinístico. Los parámetros del nodo (periodos de SMA, ADX, ATR, Bollinger, confirm bars) son optimizables en el tester.
Un saludo,
Ignacio
2 Me gusta
Hola. Una pregunta sobre el DQN y el Agente Critico. Veo que los usas (en los ejemplos de la biblioteca) mas conectados a COMPRAS y VENTAS (nodos). Sin embargo, no se podria conectar mejor al Strategy Agent para como una gestion mas automatizada y con SL y TP variables basados en ATR? Pues veo que lo conectas a compras y ventas con SL y TP fijos. O es que el DQN y Critic envian su SL y TP sugerido por dentro o algo asi?
1 me gusta
Hola Rafa,
Buena pregunta. Para ir al grano:
El DQN y el Actor-Critic NO envían SL ni TP. Solo emiten señales: buySignal, sellSignal y closeSignal. Son nodos que deciden cuándo operar, no cómo gestionar las órdenes. Por eso en los ejemplos se conectan a Compras/Ventas con SL/TP fijos en parámetros: porque ellos no calculan stops.
Sí, conectarlos al Strategy Agent es una muy buena idea si quieres gestión más automatizada con SL/TP variables basados en ATR.
El Strategic Agent (1 señal) y el Multi-Strategic Agent (hasta 5 señales) sí gestionan SL/TP internamente: auto-calibración por ATR, Q-Learning para elegir niveles dentro de rangos (min/max) y adaptación al régimen (tendencia, rango, caos…). Puedes:
-
Strategic Agent: Conectar DQN y Actor-Critic al Ensemble Voter (votan entre ambos) y la salida del voter a buyCondition/sellCondition del Strategic Agent.
-
Multi-Strategic Agent: Conectar DQN directamente a buySignal3/sellSignal3 y Actor-Critic a buySignal5/sellSignal5. Cada uno aprende en su slot y el agente gestiona SL/TP por ATR.
Si prefieres seguir con Compras/Ventas explícitos (action.buy/action.sell), añade un nodo de SL/TP dinámico:
-
SL/TP from ATR + R:R (Logic → Math): Emite precios (Buy SL Price, Buy TP Price, etc.) listos para conectar a slPrice y tpPrice de action.buy/action.sell. Pones el nodo Buy/Sell en modo “Dynamic Price (from input)” y listo.
-
AI Dynamic SL/TP (ai.dynamicSLTP): Emite SL y TP en puntos. El SL puedes conectarlo a la entrada SL Pips (dynamic) del action.buy/sell; para el TP, el nodo de acción no tiene entrada de TP en puntos (solo tpPrice en precio), así que aquí tendrías que usar el parámetro fijo de TP o combinar con otro nodo. Para SL+TP dinámicos completos y sencillos, SL/TP from ATR + R:R suele ser más directo.
Sintetizando el tema, DQN y Actor-Critic solo dan la señal, para SL/TP variables, o bien los conectas al Strategic/Multi-Strategic Agent (que ya lo incluye) o añades SL/TP from ATR + R:R (o AI Dynamic SL/TP para el SL) antes de las acciones.
Un saludo,
Ignacio
2 Me gusta
Hola. Una duda que quizas has explicado, pero en verdad tengo ciertas lagunas. Tengo el Strategy Agent. Quiero hacerle un entrenamiento, es decir, un backtest. Imagina le pongo una semilla fija = 123123. Con ese QTable que se genero, voy a demo. En demo quiero que no aprenda tanto, solo un poco, y se guie por lo que ya aprendio en el backtest.
Siendo bien especifico, que valores colocar y que parametros afectar en backtest para entrenarse y que valores colocar y que paramentros afectar en demo/real para que se comporte de acuerdo al entrenamiento, pero que siga aprendiendo pero un poco menos.
Hola Rafa,
Para entrenar en backtest con semilla fija y luego usar esa Q-Table en demo aprendiendo poco, haz lo siguiente.
En el backtest (entrenamiento)
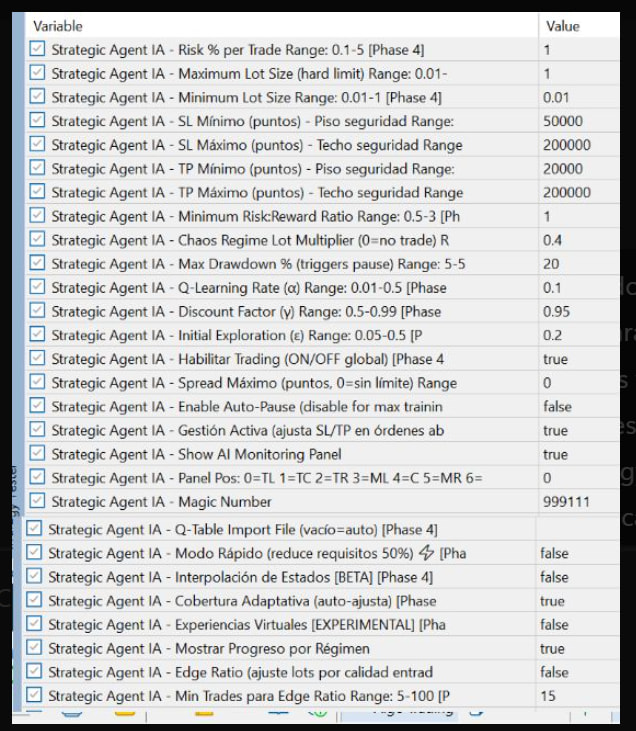
En los inputs del EA pon ReproducibilitySeed = 123123 para que cada prueba sea idéntica. En el nodo Strategic Agent deja Q-Learning Rate (α) en 0.1, Initial Exploration (ε) en 0.2 y Discount Factor (γ) en 0.95. Usa un Magic Number concreto (por ejemplo 999111) y déjalo igual siempre para ese agente. Q-Table Import File debe estar vacío para que empiece de cero y, al terminar el backtest, se guarde la Q-Table en la carpeta Common con un nombre del tipo T4_AI_QTable_999111_Symbol.bin. Desactiva Enable Auto-Pause para que el entrenamiento no se corte por drawdown. Con eso el agente entrena a ritmo normal (en Strategy Tester el código ya multiplica el learning rate por 2).
En demo o real
Para que use lo aprendido y solo aprenda un poco más, la Q-Table tiene que ser la misma. Con el mismo Magic Number y el mismo símbolo que en el backtest, el EA busca solo el archivo en Common y la carga, no hace falta poner nada en Q-Table Import File. Si usas otro Magic o quieres forzar un archivo concreto, indica en Q-Table Import File el nombre del .bin que generaste en el backtest. Para que “aprenda menos” en demo, baja el Q-Learning Rate (α) a algo como 0.03–0.05 (por ejemplo 0.04); así la tabla se actualiza más suave y el agente se guía sobre todo por lo que ya aprendió. Initial Exploration (ε) puedes dejarla en 0.05–0.10: si la Q-Table se carga, se usa el epsilon guardado en el archivo. El Discount Factor (γ) mantenlo en 0.95. Es recomendable activar Enable Auto-Pause en demo/real para limitar el drawdown.
Un saludo,
Ignacio
1 me gusta