Actualización Techain — 25 Febrero 2026
¡Hola a todos!
Compartimos las mejoras y novedades que hemos incorporado desde la última actualización. Gracias por vuestra confianza y por seguir construyendo con nosotros.
Nuevos nodos
Agente Multi-Estratégico IA (ai.multiStrategicAgent) Fase Beta
Hemos incorporado un nuevo nodo de agente IA pensado para quienes queréis integrar los cinco generadores de señales IA en un solo bot FULL IA y que cada uno aprenda de forma independiente.
¿Qué problema resuelve?
Con el Strategic Agent IA existente, cuando hay una operación abierta, el agente no tiene en cuenta el resto de señales: solo gestiona una posición a la vez. Muchos usuarios pedían poder conectar los cinco nodos generadores (Random Forest, SVM, DQN, Predictor Neuronal, Señal Libre), operar con lo mejor de cada uno y que cada señal tuviera su propio aprendizaje.
Características del Agente Multi-Estratégico IA:
-
5 slots independientes: Hasta 5 pares de señales (buy/sell) más una entrada global (ideal para conectar el Ensemble Voter).
-
5 Q-Tables separadas: Cada slot aprende con su propio Q-Learning; el rendimiento de un generador no contamina al resto.
-
Hasta 5 posiciones simultáneas: Una posición por slot, cada una con su propio Magic Number (baseMagic + 0..4) para identificar órdenes.
-
Protección de drawdown global: Si la suma del drawdown de todas las posiciones supera el límite configurado, no se abren nuevas operaciones hasta recuperar.
-
Reducción de riesgo por slot activo: Opción para reducir el lote cuando hay varias posiciones abiertas (riesgo total más controlado).
-
Chaos Lot Multiplier: Reduce o elimina el lote en régimen caótico (0 = no opera en caos).
-
Auto-Pause: Pausa inteligente que detiene el trading (no el aprendizaje) si el rendimiento se degrada.
-
Gestión Activa SL/TP: Ajusta SL/TP en las órdenes abiertas cuando el agente recalcula parámetros más conservadores.
-
Opciones avanzadas de aprendizaje: Modo rápido (
 reduce requisitos al 50%), interpolación de estados [BETA], cobertura adaptativa, experiencias virtuales [EXPERIMENTAL] y seguimiento de progreso por régimen.
reduce requisitos al 50%), interpolación de estados [BETA], cobertura adaptativa, experiencias virtuales [EXPERIMENTAL] y seguimiento de progreso por régimen. -
Importación de Q-Tables: Portabilidad entre brokers/cuentas.
-
Persistencia: Las 5 Q-Tables se guardan automáticamente cada 5 minutos en Common/Files; al reiniciar el EA se cargan solas.
-
Panel de monitoreo: Muestra en tiempo real el estado de cada slot (abierto/idle), episodios, wins/trades y drawdown global.
-
Salidas opcionales (lila): Las 7 salidas son informativas y se muestran en color lila en el canvas.
Paridad completa: El Agente Multi-Estratégico tiene todas las funcionalidades del Strategic Agent original, adaptadas al modelo de 5 slots. No es una versión simplificada; es una extensión con paridad total de features.
Tres modos de uso:
-
Directo: Conectar los 5 generadores IA a buySignal1–5 / sellSignal1–5. Cada uno opera y aprende en su slot.
-
Voter: Conectar el Ensemble Voter a globalBuy / globalSell. Una sola señal consensuada, con Q-Learning encima.
-
Mixto: Algunos slots con señales directas y la señal global del voter como respaldo.
El nodo está documentado en la formación Techain (capítulo 10.22 en español e inglés).
Mejoras en nodos existentes
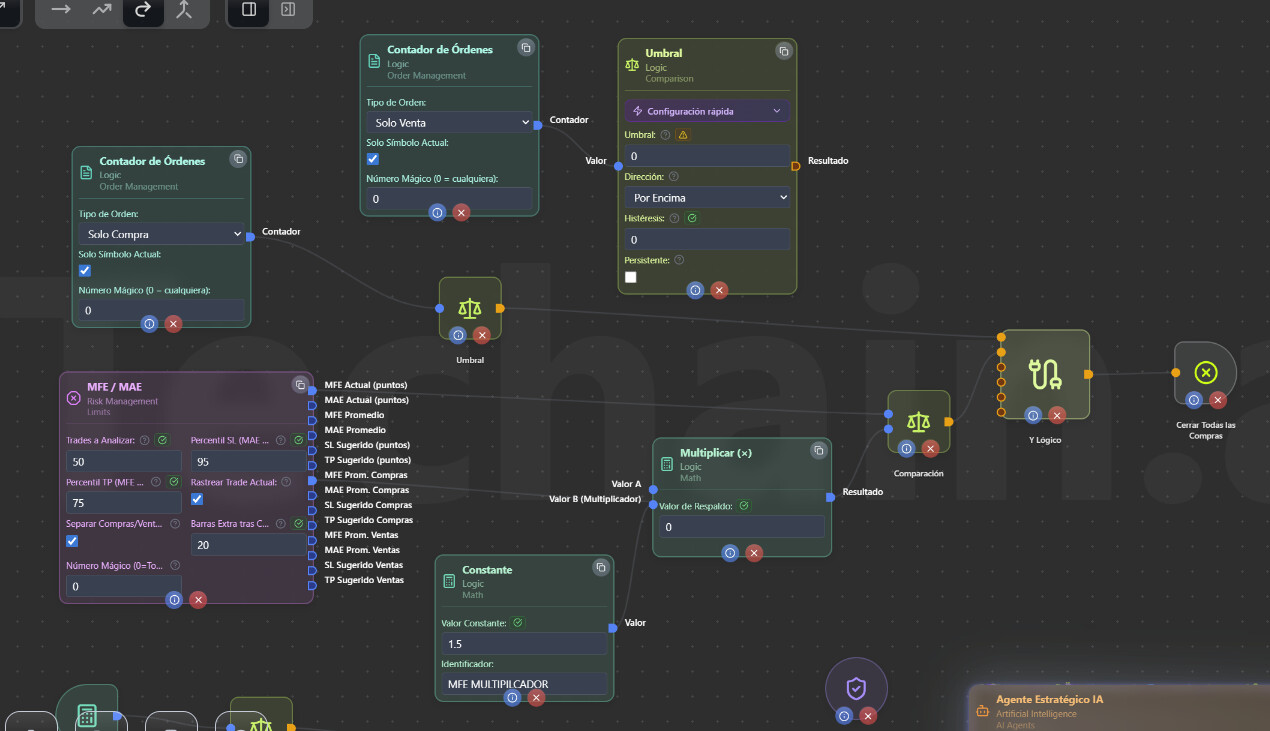
MFE / MAE — Dos mejoras importantes
El nodo MFE / MAE (Maximum Favorable Excursion / Maximum Adverse Excursion), que analiza el historial de vuestras operaciones cerradas para sugerir SL y TP óptimos basados en datos reales, ahora incluye dos nuevas opciones:
1. Separar Compras y Ventas
Hasta ahora, el nodo calculaba las estadísticas (promedios, percentiles, SL/TP sugeridos) mezclando todas las operaciones, tanto compras como ventas. Pero sabemos que muchas veces las compras y las ventas no se comportan igual: pueden tener distinta agresividad, distinto recorrido a favor y en contra.
Con la nueva opción “Separar Compras/Ventas”, al activarla aparecen 8 salidas adicionales con estadísticas independientes:
-
Para Compras: MFE Promedio, MAE Promedio, SL Sugerido y TP Sugerido calculados solo con los trades de compra.
-
Para Ventas: MFE Promedio, MAE Promedio, SL Sugerido y TP Sugerido calculados solo con los trades de venta.
Así podéis conectar el SL/TP sugerido de compras al nodo Buy y el SL/TP sugerido de ventas al nodo Sell, obteniendo niveles optimizados para cada dirección por separado.
Las salidas combinadas (que ya existían) siguen funcionando igual, así que las estrategias que ya teníais no se ven afectadas.
2. Ventana de observación extendida (Barras Extra tras Cierre)
Esta mejora resuelve un problema sutil pero importante: si usáis MFE/MAE para cerrar operaciones antes de tiempo (por ejemplo, “cerrar si MAE Actual > SL Sugerido”), esas operaciones entran en el historial con un MFE/MAE “recortado” (solo lo que duró hasta el cierre anticipado). Con el tiempo, esto puede hacer que los promedios bajen y las sugerencias se vuelvan cada vez más conservadoras, porque el nodo no ve el recorrido completo que habría tenido el precio.
Con la nueva opción “Barras Extra tras Cierre”, podéis indicar un número de barras (por ejemplo, 20) que el nodo usará para extender la ventana de observación más allá del cierre real de cada operación. Es decir, aunque cerrasteis el trade en la barra X, el nodo mira lo que hizo el precio hasta la barra X + 20 para calcular el MFE y MAE. Así las estadísticas reflejan el potencial real del movimiento del precio, no un valor “recortado” por el cierre anticipado.
-
Valor 0 (por defecto): Comportamiento estándar, solo mira desde apertura hasta cierre.
-
Valor > 0: Extiende la ventana N barras más allá del cierre. Recomendado: 10–30 barras si usáis reglas de cierre basadas en MFE/MAE.
Switch (logic.switch) — Auto-reset por barras (ventana rodante)
El nodo Switch (Hold Until Opposite) mantiene la señal activa hasta que llega la señal opuesta o expira un auto-reset. Hasta ahora solo permitía auto-reset por tiempo (minutos). A partir de esta actualización incorpora auto-reset por barras (velas).
¿Qué problema resuelve?
En estrategias basadas en cruces (por ejemplo EMA rápida/lenta), el cruce es un evento puntual: solo es verdadero en la barra exacta donde ocurre. Si necesitáis que dos cruces distintos (p. ej. EMA5/EMA13 y EMA8/EMA13) se cumplan a la vez para entrar, en la práctica casi nunca coinciden en la misma barra. La solución es “recordar” cada cruce con un Switch. Pero sin límite en el tiempo, el switch podía quedar activo demasiado tiempo y dar entradas tardías. Faltaba poder decir: “este cruce es válido solo durante N velas”.
Nuevo parámetro: Auto Reset (barras)
-
Auto Reset (barras, 0 = off): Número máximo de velas que el switch permanece en ON después de activarse. Pasadas esas N barras, el switch vuelve al estado inicial (OFF por defecto) aunque no haya llegado la señal de desactivación.
-
Uso típico: Estrategias con ventana rodante (rolling window): por ejemplo, un cruce alcista de EMAs que solo consideráis válido si el resto de condiciones se confirman en las próximas 10–20 velas. Si no se confirman a tiempo, el cruce se descarta.
-
Optimización: El parámetro es optimizable en backtesting, así que podéis probar distintas ventanas (5, 10, 15, 20 barras, etc.) para encontrar la que mejor se adapte a vuestro timeframe y activo.
-
Compatible con el reset por tiempo: Podéis usar a la vez Auto Reset (minutos) y Auto Reset (barras); el que se cumpla primero resetea el switch.
La documentación de formación (cap. 4 — Lógica) y los detalles del nodo en la app incluyen ejemplos de uso con ventana rodante (p. ej. estrategia EMA 5-8-13 + PSAR).
Votación Ensemble IA — De 3 a 5 estrategias
El nodo Votación Ensemble IA (ai.ensembleVoter) pasa de soportar 3 estrategias a hasta 5 estrategias.
-
Nuevas entradas:
buySignal4/sellSignal4ybuySignal5/sellSignal5, para conectar un cuarto y quinto generador de señales. -
Pesos adaptativos: Siguen ajustándose automáticamente por rendimiento; ahora se rastrean y muestran los pesos de las 5 estrategias (W1–W5) en el panel.
-
Métodos de votación: Majority, Weighted y Unanimous funcionan igual; con 5 estrategias, por ejemplo, un umbral del 60 % equivale a que 3 de 5 coincidan para dar señal.
-
Interfaz: El nodo tiene tamaño adaptado cuando está plegado para que entren bien todas las conexiones (10 entradas + 5 salidas).
Así podéis conectar los cinco generadores IA (Random Forest, SVM, DQN, Predictor Neuronal, Señal Libre) al Ensemble Voter y combinar su votación con el Agente Multi-Estratégico IA para que cada señal también aprenda de forma independiente. La documentación de formación (cap. 10.10) está actualizada en español e inglés.
Strategic Agent IA y Multi-Strategic Agent IA — Aprendizaje adaptativo y auto-calibración SL/TP
A partir de vuestras pruebas con Random Forest + Strategy Agent y optimizaciones solo con SL/TP min-max, hemos incorporado mejoras que abordan directamente las inquietudes sobre el aprendizaje en el tiempo y la elección de rangos de SL/TP.
1. Auto-calibración de SL/TP basada en ATR
Si los límites SL mínimo/máximo y TP mínimo/máximo no se corresponden con la volatilidad real del activo y temporalidad, la IA queda “estrangulada” y no puede colocar SL/TP óptimos. Para evitarlo:
-
Al iniciar el EA, el sistema calcula el ATR del activo en la temporalidad seleccionada y sugiere rangos razonables (por ejemplo ~0,5x–3x ATR para SL y ~1x–6x ATR para TP).
-
En el terminal (Experts) se muestra un bloque de diagnóstico con:
-
ATR actual en puntos.
-
SL/TP sugeridos (min/max) según ATR.
-
SL/TP configurados por el usuario.
-
Si los valores configurados están claramente fuera de rango (por ejemplo SL máximo muy bajo respecto al ATR), el EA los ajusta automáticamente a los sugeridos y lo indica en el log.
-
Las etiquetas de los parámetros en la app incluyen ahora una guía rápida: SL Mínimo [~0,5x ATR], SL Máximo [~3x ATR], TP Mínimo [~1x ATR], TP Máximo [~6x ATR].
Así podéis seguir optimizando SL/TP min-max en el Strategy Tester, pero con una referencia clara al arrancar y con corrección automática cuando la configuración no cuadra con el activo.
Aplicado en: Strategic Agent IA, Multi-Strategic Agent IA y nodo AI Dynamic SL/TP.
2. Mitigación del sobreajuste en backtest
En backtests largos (por ejemplo 1 año), el aprendizaje acelerado podía hacer que el agente se “enganchara” a patrones del inicio del período y empeorara hacia el final. Hemos ajustado:
-
Suelo de exploración (epsilon) en backtest: se mantiene un mínimo de exploración (5 %) para no dejar de explorar por completo; con el ALS (VDBE, véase más abajo), cuando el modelo se equivoca el epsilon puede subir por encima de ese mínimo.
-
Decay de exploración más suave en backtest, para que la IA no “cierre” la exploración demasiado pronto.
-
Límite del learning rate en las actualizaciones de la Q-Table y en el replay reducido (cap en 0,35), para evitar convergencias demasiado agresivas.
-
Multiplicador de velocidad de entrenamiento en backtest reducido de 3x a 2x.
Con esto se reduce el riesgo de que el bot “aprenda solo el pasado reciente” del backtest y falle cuando el mercado cambia.
3. Sistema de Aprendizaje Adaptativo (ALS)
Una preocupación razonable es: si el bot ya ha aprendido y deja de explorar, pero con el tiempo empieza a perder, ¿no debería volver a explorar para adaptarse? Hemos implementado un Sistema de Aprendizaje Adaptativo (ALS) inspirado en técnicas de la literatura (VDBE, ventanas de rendimiento, factor de olvido, soft reset):
Epsilon adaptativo (VDBE — Value-Difference Based Exploration)
-
El TD-error (diferencia entre el valor Q antiguo y el nuevo tras cada trade) mide la “sorpresa” del modelo: si se equivoca mucho, el error es alto.
-
Cuando el TD-error es alto, el epsilon sube (el bot explora más). Cuando es bajo, el epsilon baja (explotación).
-
Así, si el mercado cambia y el modelo empieza a equivocarse, la exploración se reactiva automáticamente sin depender solo del tiempo.
Ventana móvil de rendimiento (rolling window)
-
Se mantiene una ventana de los últimos 20 trades con win rate, profit factor y rachas de pérdidas.
-
Con esto se detecta degradación reciente (no solo el resultado acumulado desde el inicio).
Niveles de degradación y acciones automáticas
-
Nivel 0 (OK): Sin acción.
-
Nivel 1 (leve): Win rate reciente < 40 % o 4+ pérdidas consecutivas → subida de epsilon (mínimo 8 %) para re-explorar.
-
Nivel 2 (moderada): WR < 30 % o 6+ pérdidas consecutivas → soft reset del 30 % de la Q-Table y epsilon mínimo 15 %.
-
Nivel 3 (severa): WR < 20 % o 8+ pérdidas consecutivas → soft reset del 60 % y epsilon mínimo 25 %.
Entre resets se aplica un enfriamiento (p. ej. mínimo 10 episodios) para no reaccionar en exceso a rachas cortas.
Decay de la Q-Table (factor de olvido)
-
Periódicamente se aplica un decay a todos los valores Q (p. ej. 2–20 % según nivel de degradación).
-
Los patrones muy antiguos pierden peso y lo recién aprendido tiene más influencia.
Experience replay con peso por recencia
-
En el replay priorizado, las experiencias recientes se muestrean con mayor probabilidad (half-life de 7 días en vivo, 30 días en backtest).
-
Las experiencias antiguas siguen contribuyendo pero con menos peso.
Nuevos parámetros en la app
-
Aprendizaje Adaptativo (ON/OFF): Activa o desactiva todo el sistema ALS (por defecto ON).
-
Sensibilidad a degradación: Conservador / Balanceado / Agresivo, para ajustar cuándo se considera que hay degradación y se disparan las acciones anteriores.
El estado del ALS (ventana reciente, rachas de pérdidas, etc.) se persiste en el archivo de la Q-Table, de modo que al reiniciar el EA se mantiene la coherencia del aprendizaje adaptativo.
Resumen: Los bots IA con Strategic Agent o Multi-Strategic Agent pueden ahora volver a explorar y adaptarse cuando el rendimiento reciente empeora, en lugar de limitarse a pausar o seguir explotando una política obsoleta.
Nuevas funcionalidades
No hay otras nuevas funcionalidades en esta actualización además de las descritas en los apartados anteriores.
Mejoras de interfaz y experiencia
Validación inteligente de conexiones entre nodos
Gracias a una sugerencia de la comunidad, hemos añadido un sistema de validación semántica que impide conectar nodos que, aunque parezcan compatibles por su tipo de dato, no funcionarían correctamente juntos.
¿Qué problema resuelve?
Hasta ahora, era posible conectar nodos que compartían el mismo tipo de dato (por ejemplo, un valor numérico) pero que en la práctica no tenían sentido funcional juntos. Esto podía generar confusión, porque el bot se creaba sin errores aparentes pero luego no funcionaba como se esperaba.
Ejemplo práctico: El nodo Puerta de Confianza IA necesita recibir un score de confianza (0–100) que solo generan nodos como Random Forest, SVM o Predictor Neuronal. Si conectabas un nodo que no proporciona ese score, el bot se compilaba pero nunca abría operaciones, sin que quedara claro por qué.
¿Qué cambia ahora?
-
Si intentas hacer una conexión no compatible, el sistema la bloquea y te muestra un aviso claro indicando por qué no se puede conectar y qué nodos sí son compatibles con esa entrada.
-
Esta validación también se aplica durante la compilación, como red de seguridad adicional.
-
Las conexiones que ya funcionaban correctamente no se ven afectadas en absoluto.
Esta mejora ayuda a evitar falsas expectativas y facilita la creación de bots en el canvas, especialmente para quienes están empezando.
Documentación de formación
-
Cap. 4 — Lógica / Logic: Actualizado el nodo Switch con el nuevo parámetro Auto Reset (barras) y descripción de su uso en estrategias con ventana rodante (rolling window), en español e inglés.
-
Cap. 10.10 — Votación Ensemble IA / Ensemble Voter AI: Actualizado a 5 estrategias (entradas 4 y 5, ejemplos, umbrales y diagramas) en español e inglés.
-
Cap. 10.22 — Agente Multi-Estratégico IA / Multi-Strategic Agent AI: Nuevo capítulo en español e inglés con descripción del nodo, modos de uso (directo, voter, mixto), parámetros, opciones avanzadas de aprendizaje, gestión activa, auto-pause, chaos lot y ejemplos de conexión. Actualizado con paridad completa de features respecto al Strategic Agent.
Estabilidad y seguridad
Seguimos trabajando en la estabilidad y seguridad del servicio para que podáis usarlo con total tranquilidad.
Próximos pasos
-
Entradas de SL/TP externos en el Strategy Agent IA — Estamos trabajando para que podáis conectar directamente las salidas del nodo MFE/MAE (u otros) al Strategy Agent, para que use esos valores en vez de su propio ATR.
-
Seguimos escuchando vuestras ideas y sugerencias. Algunas de las mejoras de esta actualización vienen directamente de propuestas de la comunidad.
Gracias por formar parte de la comunidad Techain. Cualquier duda o sugerencia, ya sabéis dónde estamos.
— El equipo Techain